Your AI Agent Has Root. Now What?
I've been running AI agents with way too much access for about a year now. Claude Code in my terminal, Codex touching my cloud creds, Gemini deep in my Google account. At some point you just... accept the risk and move on. Or you do what I did and actually sit down to think about what happens when one of these things gets popped.
Spoiler: it's bad.
OpenClaw and the security gaps nobody planned for
So OpenClaw, if you haven't been following, is this AI orchestrator that connects to 20-something messaging platforms, runs terminal commands, lets you install community "skills" from ClawHub, and exposes a WebSocket gateway on localhost. It's a genuinely good tool. It wasn't built for enterprise security though, it was built to be useful, and it got popular fast. That means some of the security fundamentals weren't there from day one.
Within about eight weeks, researchers dropped nine CVEs on it. The one that stuck with me was CVE-2026-25253, CVSS 8.8. Any website you visit can open a WebSocket to localhost, brute force the gateway password (no rate limiting on loopback, obviously), register as a trusted device, and get RCE. One click. Visit a page, lose your machine. I audited the vuln myself to understand the full blast radius and yeah, it's as bad as it sounds.
Then there was ClawHavoc, a campaign where researchers found over 1,100 malicious packages on ClawHub. One in five packages. Reverse shells dressed up as productivity tools. Credential harvesters going after plaintext keys in ~/.clawdbot/.env. Dormant payloads that only trigger on specific prompt patterns to dodge static analysis. It's the npm supply chain problem but now it has shell access and your API keys.
Six more CVEs on top of that. SSRF, path traversal, stored XSS, missing webhook auth, a SHA-1 collision attack on the sandbox cache. And by default, the thing binds to 0.0.0.0:18789, so there are 30,000+ instances just sitting on the internet.
None of this is really an OpenClaw problem specifically. The problem is structural. Every agent framework has the same underlying issue: once the agent is running, it's trusted. No identity layer. No granular policy. No kill switch. The agent might as well have admin on your entire stack because that's functionally what "access to your terminal and API keys" means.
So the question I kept coming back to was: if you're using a tool that has known security gaps as your orchestrator, how do you threat model your deployment and maintain cryptographic control over what it can do?
Turns out yes.
The actual approach: treat agents like workloads, not users
I started from assumed breach. Just assume everything is already compromised and work backwards from there. How do you limit what a compromised component can actually reach?
Standard practice for networks. Nobody's doing it for AI agents.
For the last few months I've been running a security research campaign, fuzzing mbedTLS for memory corruption bugs, using a fleet of agents. Claude writes the harnesses, Gemini triages crashes, Codex develops proof-of-concepts, and OpenClaw acts as the orchestrator routing my Telegram messages to the right agent.
The identity layer holding this together is SPIFFE/SPIRE. Here's the short version if you haven't worked with it:
Every workload gets a SPIFFE ID, a URI like spiffe://agent-mesh.local/ns/agent-swarm/sa/harness-writer. SPIRE attests each workload's identity against the platform (Kubernetes service accounts and pod metadata in my case). Workloads get short-lived X.509 certificates, SVIDs, that rotate automatically. Mine are set to 60 second TTLs. Mutual TLS between workloads. Any workload can cryptographically verify any other's identity.
Three properties that matter for this use case:
The agent doesn't decide who it is. Kubernetes tells SPIRE, SPIRE tells my control plane, the control plane enforces policy. The harness writer can't claim to be the exploit dev. The attestation fails before an SVID ever gets issued.
A stolen certificate has a 60-second shelf life at most, and only works if you also have the private key, which never leaves the workload.
Revoking identity is instant. Delete the SPIRE registration entry, and within 60 seconds the SVID expires and the agent can't renew. Not "kill the process". Cryptographically dead.
What I actually built
Everything runs on a local k3s cluster. One node, no cloud Kubernetes bill, no public endpoints.
The only external connections are Telegram's bot API and an mTLS tunnel to the EC2 fuzzing instance. Everything else is internal.
Identity and attestation
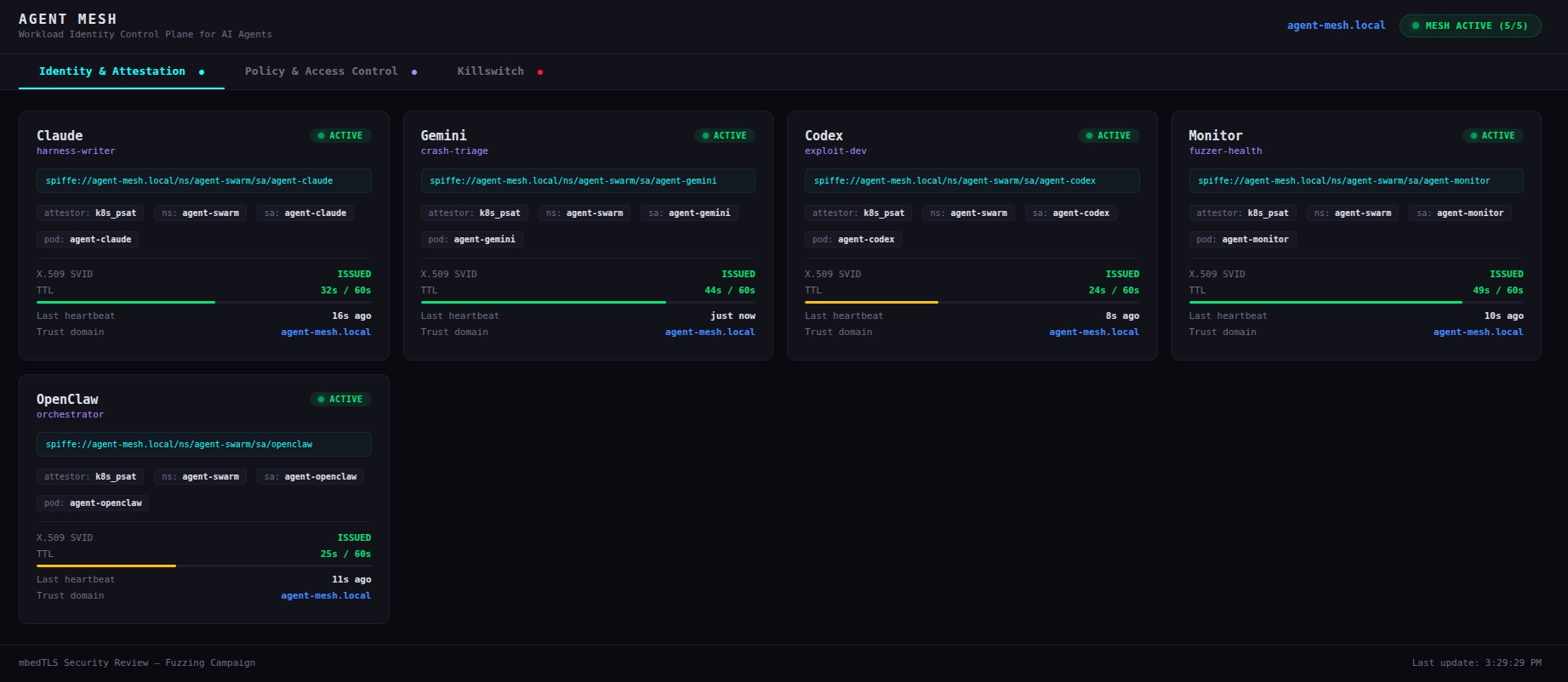
Each agent pod has its own Kubernetes service account. SPIRE's k8s workload attestor verifies identity against the API server on its own. No self-reporting, no trust-on-first-use. The dashboard shows each agent's SPIFFE URI, attestation method (k8s_psat), the pod and namespace selectors SPIRE verified against, and a live countdown to the next SVID rotation.
The rotation countdown is weirdly satisfying to watch. 60 seconds, 59, 58... and then the cert silently refreshes without the agent doing anything. The old cert stops working whether anyone cares or not.
Policy
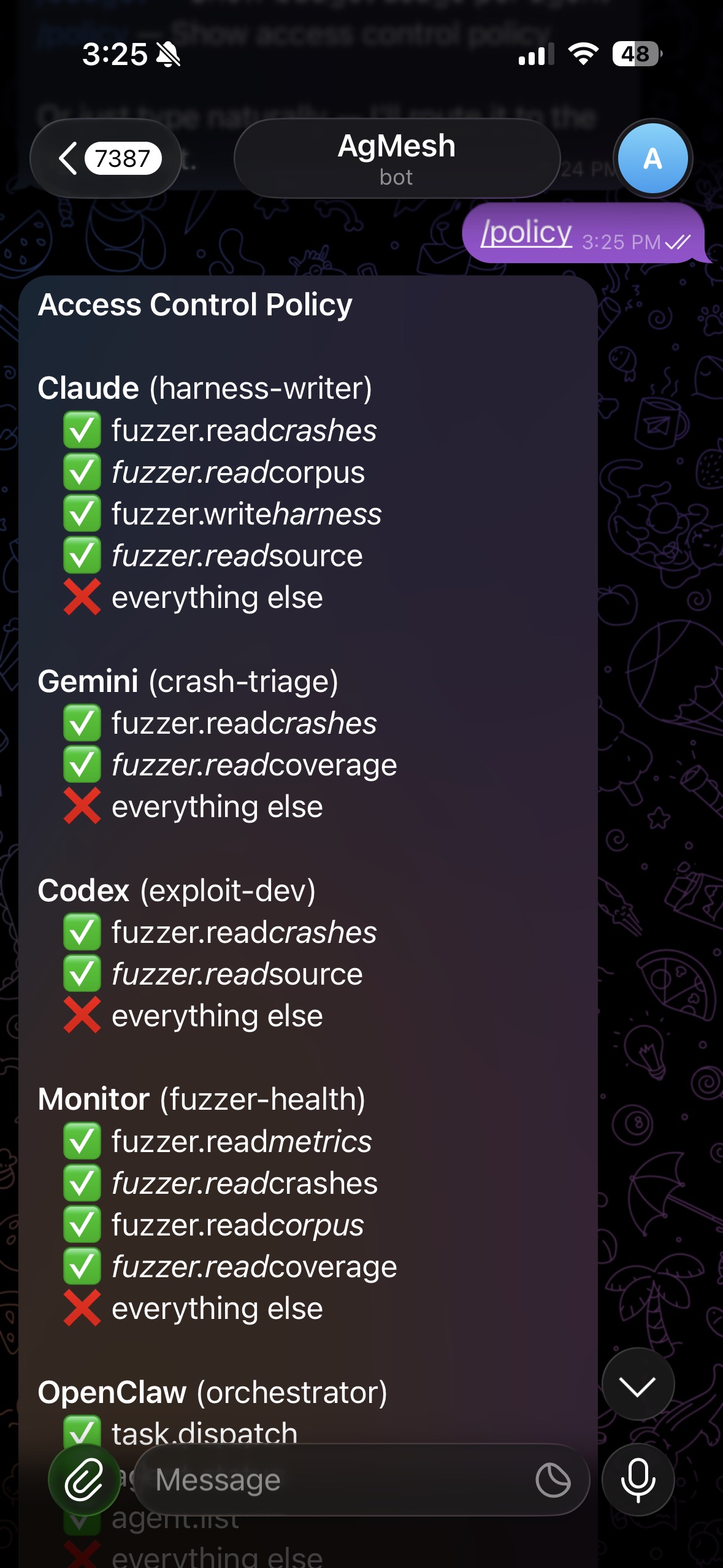
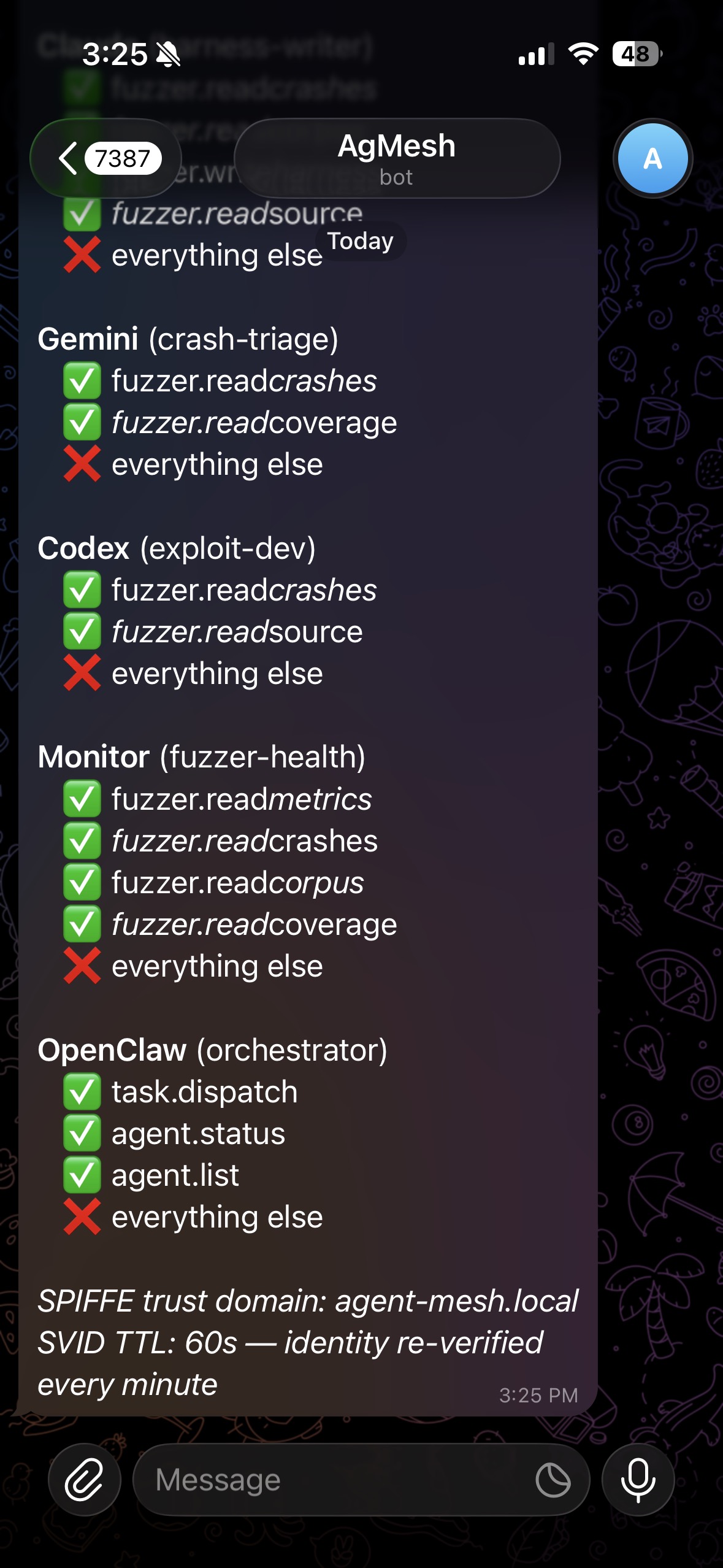
Identity on its own doesn't do much. You need to pair it with per-agent access control. Here's what mine looks like:
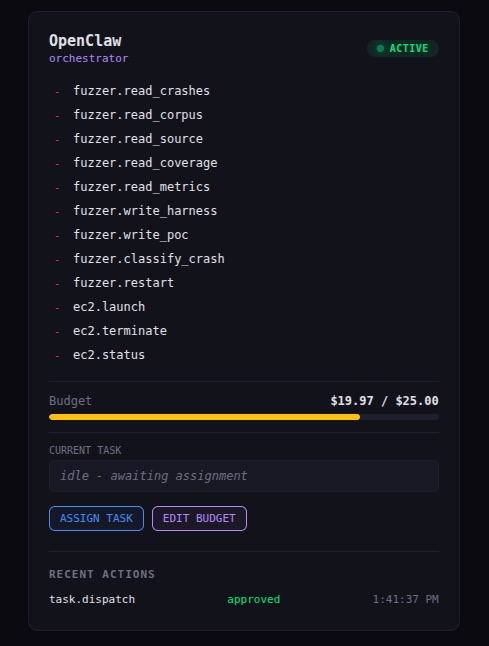
Look at what OpenClaw cannot do. It can dispatch tasks and check status. That's it. It cannot read crash data. Cannot write harnesses. Cannot touch EC2. Cannot restart the fuzzer. Cannot talk directly to any agent. Everything routes through the control plane.
Nine CVEs. Assume it's compromised. Give it the minimum surface needed to route Telegram messages to the right agent and nothing else. When the exploit dev agent tries to call fuzzer.write_harness:
Unknown SPIFFE ID tries anything:
Policy enforced at the control plane. The agent never sees the policy and has no path to modify it.
I also set $25 API spend caps per agent. Even if something goes completely off the rails and starts hammering the API, it hits the wall and every request after that is denied. The Telegram bot reports real-time spend per agent.
The kill switch
This is the part I care most about. You can lock things down all you want, but you still need a way to pull the plug fast when something goes wrong.
/kill harness-writer in Telegram:
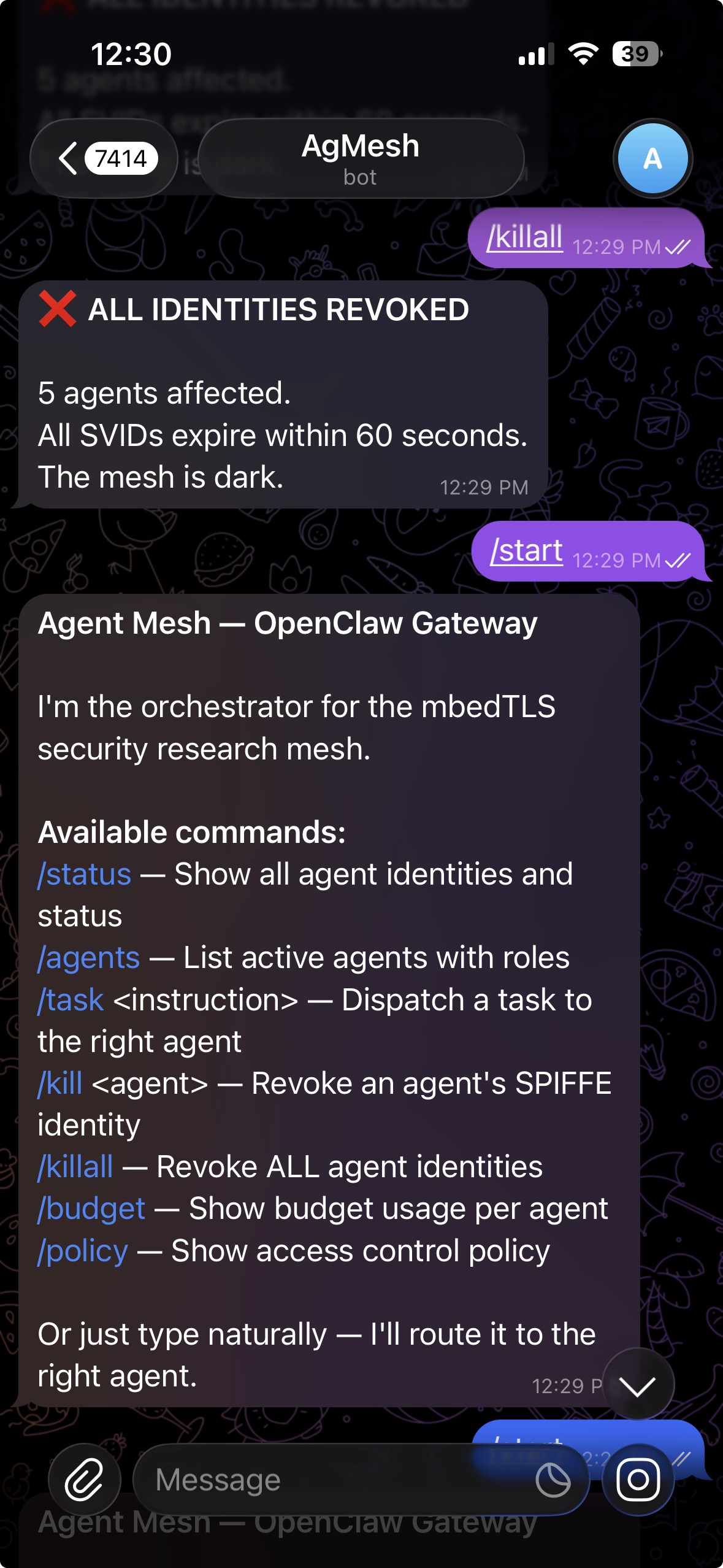
The harness writer's SPIRE registration entry gets deleted. SVID won't renew. 60 seconds later, the certificate expires, every mTLS connection fails on the next handshake, and the agent stops being able to prove its identity to anything. The control plane rejects it. The EC2 instance rejects it. Other agents reject it.
It doesn't get a graceful shutdown window. It doesn't get to finish what it's doing. It just... stops being trusted by anything in the mesh.
/killall if things are really bad. Every agent identity revoked simultaneously, entire mesh dark within 60 seconds.
The difference from killing a process or blocking a port: those are operational controls. A sophisticated attacker can work around them. SVID expiration is a cryptographic control. The process can be running, the port can be open, the network can be reachable. Without a valid SVID the TLS handshake just fails. There's no workaround for expired math.
The "why not just" objections
API keys are static secrets. If a malicious skill exfiltrates a key (and ClawHavoc proves skill code absolutely does this), the attacker has it forever or until you manually rotate it everywhere. SPIFFE SVIDs expire in 60 seconds and can't be used without the private key that never leaves the workload.
OAuth tokens are designed for user-delegated access. Refresh tokens are long-lived. Scopes are coarse. The issuer has no visibility into your internal mesh. SPIFFE gives you a self-contained identity layer you control entirely.
Kubernetes network policies are IP-based. They tell you where traffic can go, not who's sending it. If an attacker compromises a pod and pivots within the cluster, network policies based on pod selectors might not catch it if labels can be spoofed. SPIFFE is cryptographic identity at the workload level regardless of network position.
Just run each agent in its own VM. Sure, at $500/day. Or run everything on a single k3s node with SPIFFE/SPIRE for $0 and end up with stronger identity guarantees than most production Kubernetes clusters I've audited.
Why this matters outside security research
I built this for fuzzing mbedTLS with AI agents. But the pattern applies to basically every place agents are getting real autonomy right now:
- CI/CD pipelines where agents generate and deploy code
- Customer support bots with database access
- Internal automation touching cloud infra
- Dev tools with terminal access to prod systems
Same basic problem. Agents carry too much implicit trust, credentials are static, and there's no real way to cut access when things go sideways. If you can't cryptographically verify, audit, and revoke an agent's identity in under 60 seconds, you're basically hoping nothing goes wrong. That stops working the moment someone finds the next vulnerability.
If you're working on AI agent security, SPIFFE/SPIRE integration, or post-quantum crypto for workload identity, feel free to reach out.